Cosh-DiT: Co-Speech Gesture Video Synthesis via
Hybrid Audio-Visual Diffusion Transformers
2. Department of Computer Vision Technology (VIS), Baidu Inc.,
3. Tokyo Institute of Technology,
4. Department of Computer Science and Technology, Tsinghua University,
5. Department of Electronic Engineering and Information Science, University of Science and Technology of China,
6. S-Lab, Nanyang Technological University.
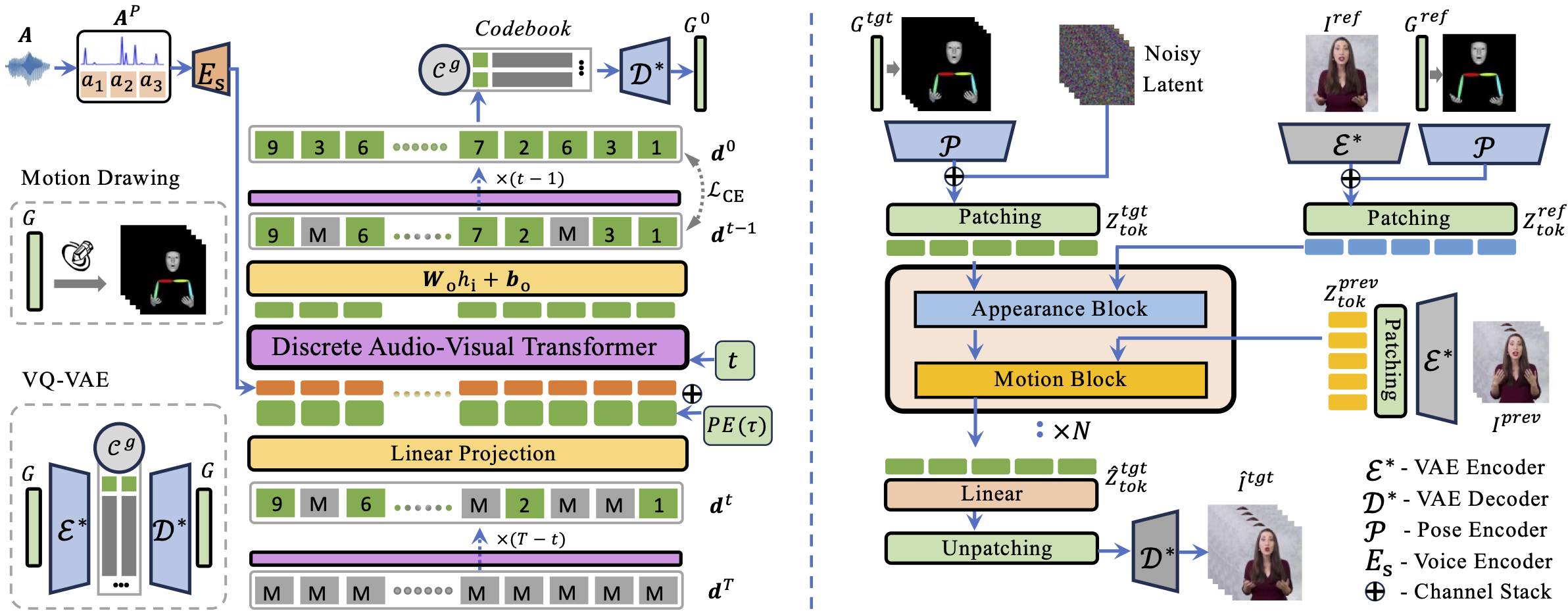
Abstract
Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
Demo Video
Materials

Citation
@misc{sun2025coshditcospeechgesturevideo,
author = {Yasheng Sun and Zhiliang Xu and Hang Zhou and Jiazhi Guan and Quanwei Yang and Kaisiyuan Wang and Borong Liang and Yingying Li and Haocheng Feng and Jingdong Wang and Ziwei Liu and Koike Hideki},
title = {Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers},
publisher = {arXiv},
year = {2025},
url={https://arxiv.org/abs/2503.09942},
copyright = {Creative Commons Attribution 4.0 International}
}